




Any application with decent traffic would always have a single entity being updated by “n” number of concurrent transactions — you can see it live when multiple users like a twitter-post or a good write-up on a personal blog :P
We definitely fancy a high concurrency and throughput for our applications for obvious reasons. Concurrency on applications means concurrency from the database (in most cases). Though DBMS providers (Oracle, Postgres etc..) abstract away the concurrency handling by 2-phase locking(2PL) or Multi-Version Concurrency Control(MVCC). But they leave out certain configurations to application developers and by default, they allow high throughput, and data conflicts are expected.
So, why would a DBMS provider allow possible data conflicts and why can’t they abstract away handling of all concurrency issues? Let’s find out…..
When we are talking about concurrency — we are talking about concurrent transactions.
A transaction is a collection of read/write operations. And a general rule that most of the database management systems apply to transactions is ACID.
A — Atomicity C — consistency I — Isolation D — Durability
In the interest of the topic, let's not delve into each one of them.
The problem comes with “I” (Isolation). Because it states that each transaction should occur independently and they do not affect each other.
We may think, “what's the problem with that?”. There is no problem if all transactions are happening serially one after the other. The problem comes when multiple transactions occur concurrently exactly at the same time on a single entity. In such scenarios, the database uses a transaction isolation technique called “serializable” using physical-locking and the outcome is the same as if the underlying transactions were executed one after the other.
We can configure the Database isolation level to “Serializable” to handle these transactions and be done with it. But as the incoming traffic grows, the price for strict data integrity becomes too high, and this is the primary reason for having multiple isolation levels.
So, Database providers offer multiple isolation levels for concurrent connections, and transaction throughput can increase, so the database system can accommodate more traffic. However, parallelization imposes additional challenges as the database must interleave transactions in such a way that conflicts do not compromise data integrity.
Before we dive into isolation levels, let’s look at some common conflicts/anomalies
Anomalies
Dirty-read:
A dirty read happens when a transaction is allowed to read the uncommitted changes of some other concurrent transaction. Taking a business decision on a value that has not been committed is risky because uncommitted changes might get rolled back.
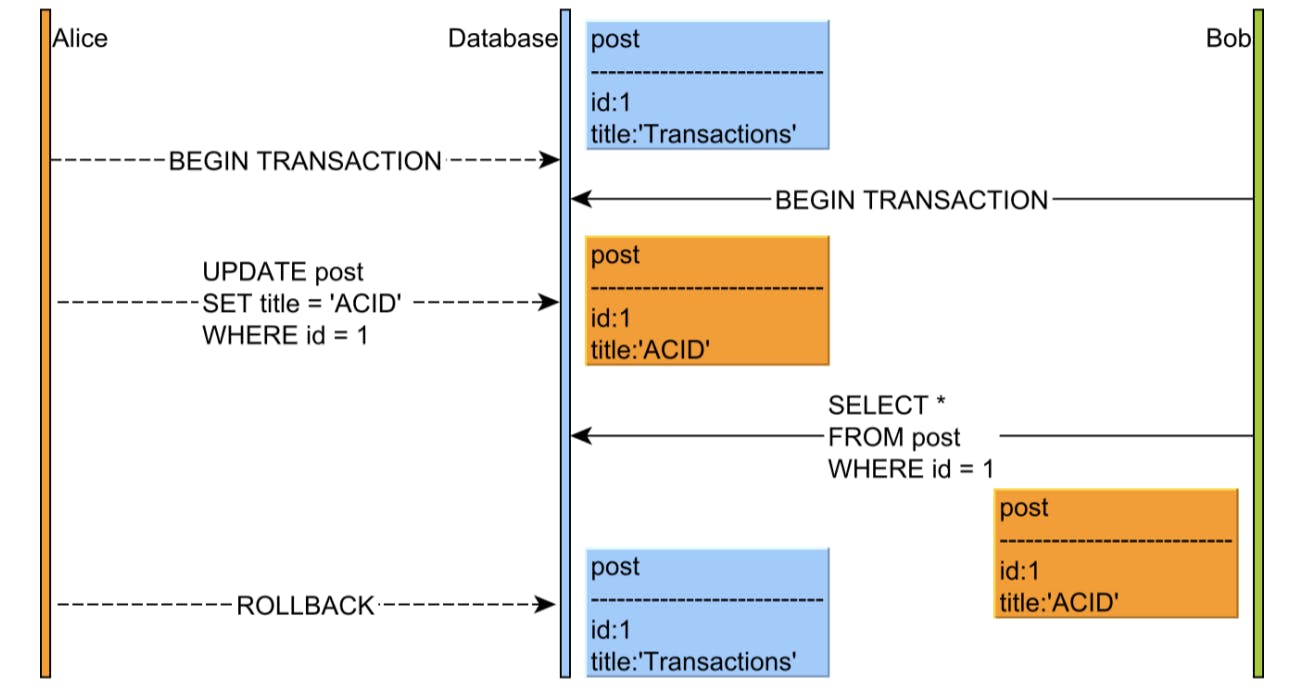
Non-Repeatable Read:
If a transaction reads a database row without applying a shared lock on the newly fetched record, then a concurrent transaction might change this row before the first transaction has ended.
The best example is, a client might order a product based on a stock quantity value that is no longer a positive integer). With the Read-Committed isolation level, it is possible to avoid non-repeatable (fuzzy) reads.
Some ORM frameworks (e.g. JPA/Hibernate) offer application-level repeatable reads. The first snapshot of any retrieved entity is cached in the currently running Persistence Context. Any successive query returning the same database row is going to use the very same object that was previously cached.
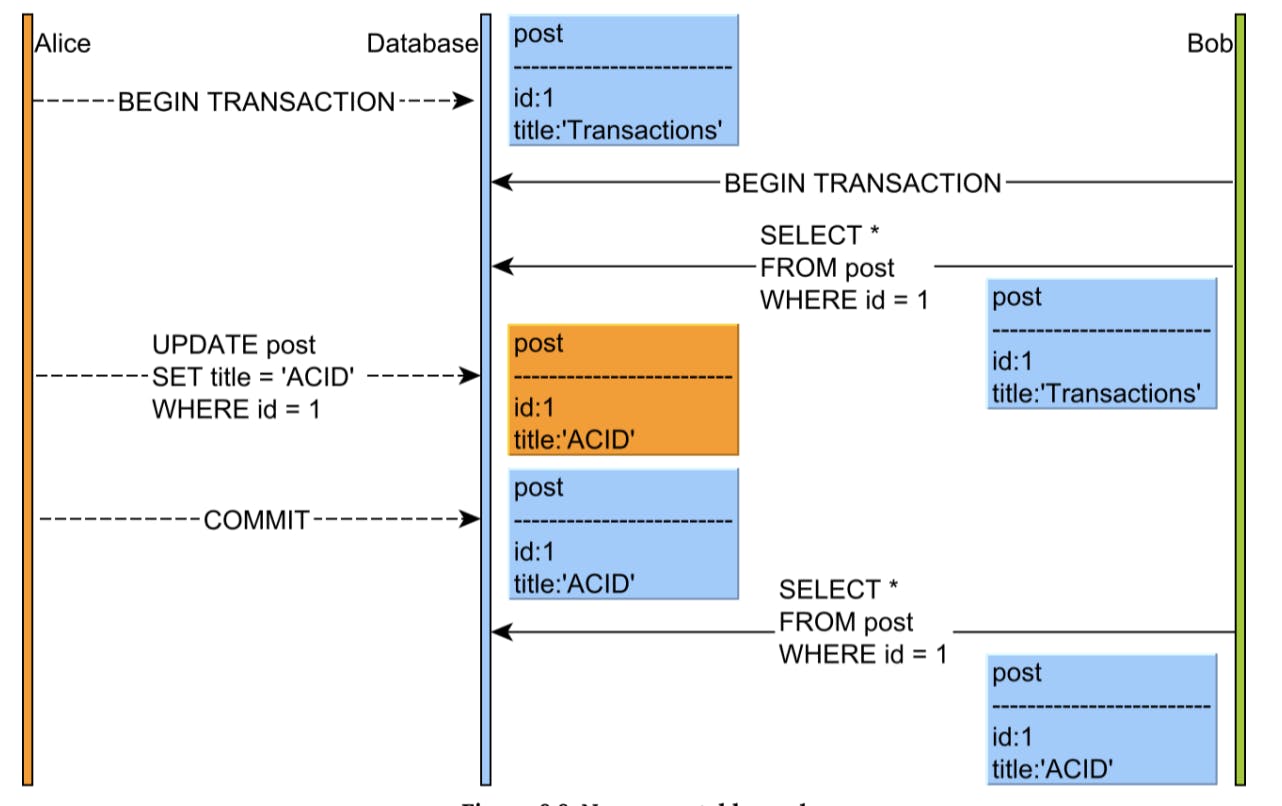
Lost Update:
This phenomenon happens when a transaction reads a row while another transaction modifies it prior to the first transaction to finish.
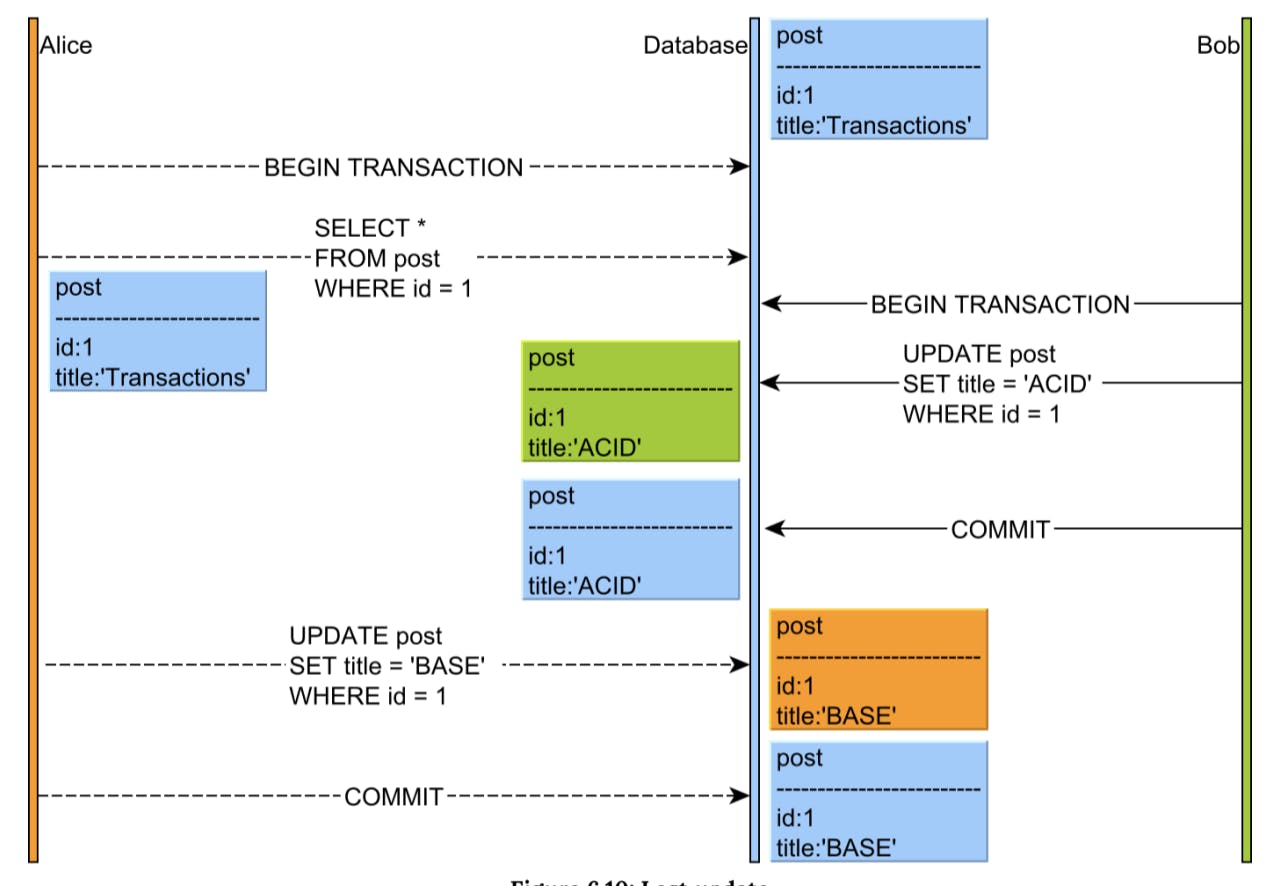
This anomaly can have serious consequences on data integrity (a buyer might purchase a product without knowing the price has just changed), especially because it affects Read Committed (the default isolation level in many database systems.)
Most ORM tools, such as Hibernate, offer application-level optimistic locking, which automatically integrates the row version whenever a record modification is issued. On a row version mismatch, the update count is going to be zero, so the application can roll back the current transaction, as the current data snapshot is stale.
Along with these, there are other anomalies like Phantom read, read-skew, and write-skew, etc...
So, there are some database-level isolation levels that can be configured.
Isolation levels
Some standard isolation levels DBMS providers have are,
Serializable
Read Committed
Read Uncommitted
Repeatable Read etc…

Application Level Transactions
However, from the distributed application perspective, a business workflow might span over multiple physical database transactions, in which case the database ACID guarantees are not sufficient anymore. A logical transaction may be composed of multiple web requests, including user think time, for which reason it can be visualized as a long conversation.
The transaction propagates from one component to the other within the service-layer transaction boundaries.
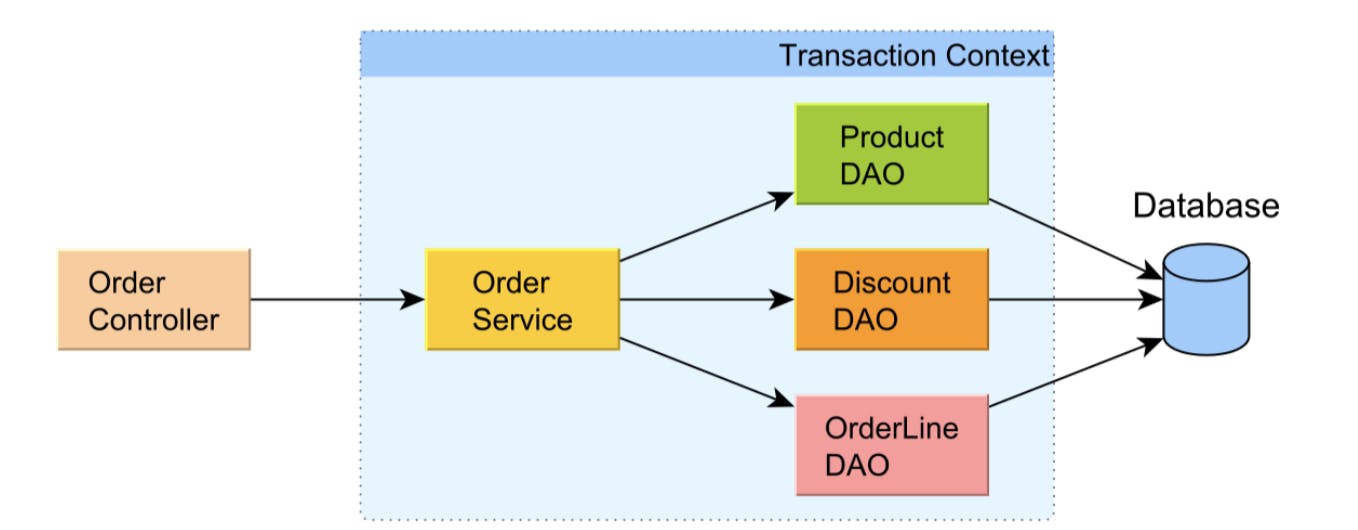
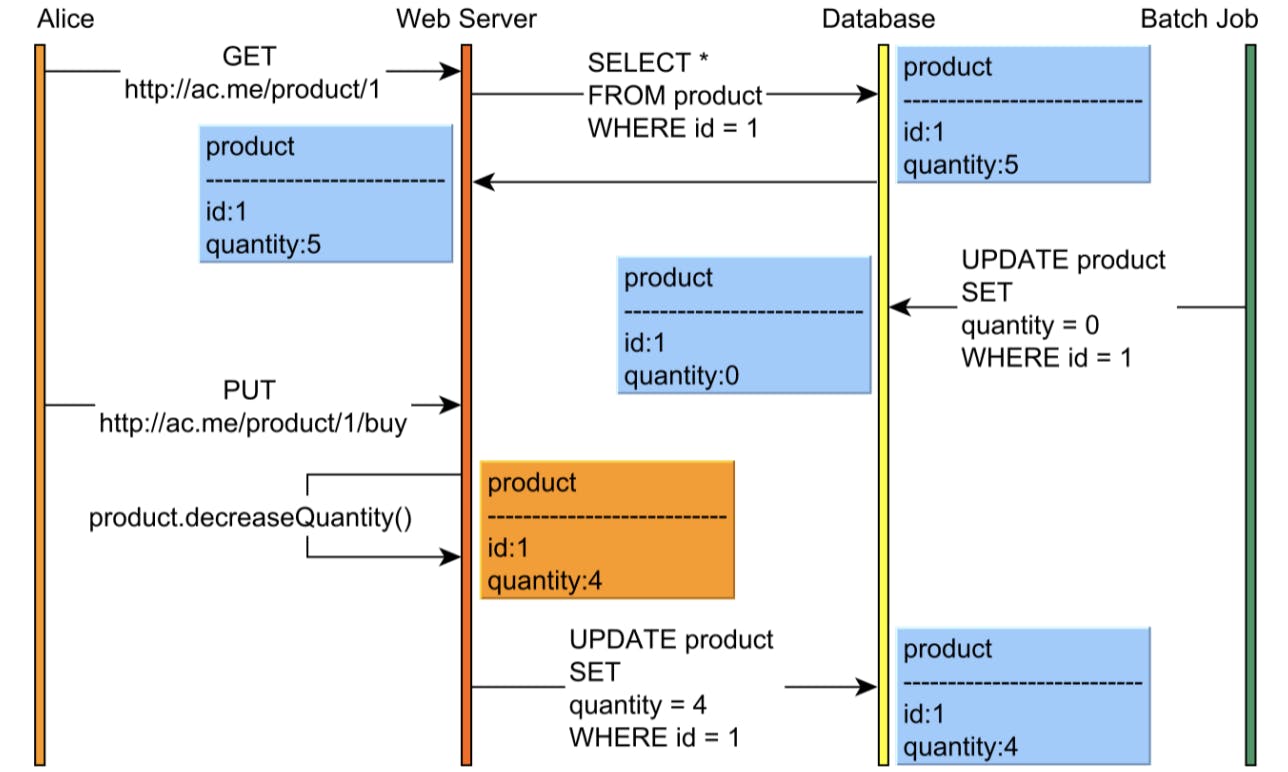
Here a batch job resets the product quantity and Alice attempts to purchase one item thinking the product version has not changed. And the batch job’s modification is just simply overwritten. (similar to lost update)
Here come the application-level locking mechanisms which many ORM frameworks provide out-of-the-box.
Locking
Database Isolation levels entail implicit locking, whether it involves physical locks (like 2PL) or data anomaly detection (MVCC).
To coordinate state changes at the application level, concurrency control makes use of explicit locking, which comes in two flavors:
Pessimistic locking
Optimistic locking
Pessimistic locking:
It assumes that conflicts are bound to happen, and so they must be prevented accordingly. (hence the name pessimistic). Usually involves manually requesting shared or exclusive locks.
Optimistic locking:
Now to the infamous Optimistic locking → Optimistic locking does not incur any locking at all. A much better name would be optimistic concurrency control since it uses a totally different approach to managing conflicts than pessimistic locking.
It assumes that contention is unlikely to happen, (hence the name optimistic) and so it does not rely on locking for controlling access to shared resources. The optimistic concurrency mechanisms detect anomalies and resort to aborting transactions whose invariants no longer hold.
One best example for optimistic locking is — ORM frameworks like Hibernate throw stale element exception when a queried-version (cached) is modified before we update (basically version mismatch). Hence avoiding lost updates.
Appreciate for reading till here and that’s all for this post. Please drop any comments/feedbacks. Cheers!!
References:
The amazing: Vlad Mihalcea