




This write-up is my own way of attempting to explain how Kafka works in simple terms
Let's see how Kafka works
One or more publishers send messages to Kafka and there could be one or more consumers consuming those messages.
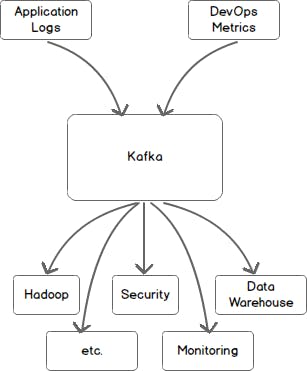
That's it !! that’s all it does and does it really well. Simply put, Kafka is just a messaging system or more like a data bus/Queue. But why all the hype and talk??
Let's Find out →
Obviously, Kafka offers some important features out of the box and also highly customizable. It is distributed in nature, highly scalable, redundant messaging, and more importantly, it is highly available and resilient to node failures and supports automatic recovery
In real-world data systems, these characteristics make Kafka an ideal fit for communication and integration between components of large-scale data systems.
But How does Kafka manages to deliver so many features and what actually is happening inside?
Before we dive in think of Kafka as a very efficient postman who delivers messages with multiple hands :P
Message:
Any data that is sent to Kafka or consumed from Kafka is called a message
Topic:
All Kafka messages are organized into topics. If you wish to send a message you send it to a specific topic and if you wish to read a message you read it from a specific topic
Partition:
Each topic again is divided into a number of partitions. Partitions allow you to parallelize a topic by splitting the data in a particular topic across multiple brokers — each partition can be placed on a separate machine to allow for multiple consumers to read from a topic in parallel
Broker:
A broker is simply an instance of Kafka. As a distributed system, Kafka runs in a cluster. Each node in the cluster is called a broker. Partitions of a topic can be placed on a separate machine to allow for multiple consumers to read from a topic in parallel.
So there is a “Topic” to which a “Message” is sent and each message is placed in some “Partition” of a topic where a consumer reads from.
Let's see what happens inside a partition while the consumers read from them
Offset:
Each message within a partition has an order called its offset. Kafka maintains this message ordering for you. Consumers can read messages starting from a specific offset and are allowed to read from any offset point they choose, allowing consumers to join the cluster at any point in time they see fit. Given these constraints, each specific message in a Kafka cluster can be uniquely identified by a tuple consisting of the message’s (topic, partition, offset) within the partition.
Consumers and Consumer Groups
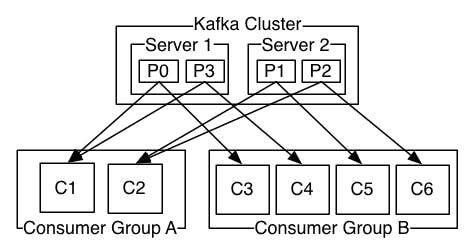
Consumers read from any single partition, each consumer within the group reads from a unique partition and the group as a whole consumes all messages from the entire topic. The following picture from the Kafka documentation describes the situation with multiple partitions of a single topic
case1:
If you have more consumers than partitions then some consumers will be idle because they have no partitions to read from.
case2:
If you have more partitions than consumers then consumers will receive messages from multiple partitions.
case3:
If you have equal numbers of consumers and partitions, each consumer reads messages in order from exactly one partition.
Server 1 holds partitions 0 and 3 and server 2 holds partitions 1 and 2. We have two consumer groups, A and B. A is made up of two consumers and B is made up of four consumers. Consumer Group A has two consumers of four partitions — each consumer reads from two partitions. Consumer Group B, on the other hand, has the same number of consumers as partitions and each consumer reads from exactly one partition.
References: